









In this short tutorial, you'll see how to do abbreviation/acronym detection and matching in Python. We will try to map abbreviations or acronyms to the full form of the names.
We will use 3 different ways for mapping and detection:
- regex builder
- using difflib library
- nlp abbreviation detection
Regex to detect abbreviations/acronym
To detect abbreviations using regex in Python we can try regex like:
r"\b[A-Z]{2,}\b"- capital letters onlyr"\b[A-Z\.]{2,}\b"- abbreviations plus dots
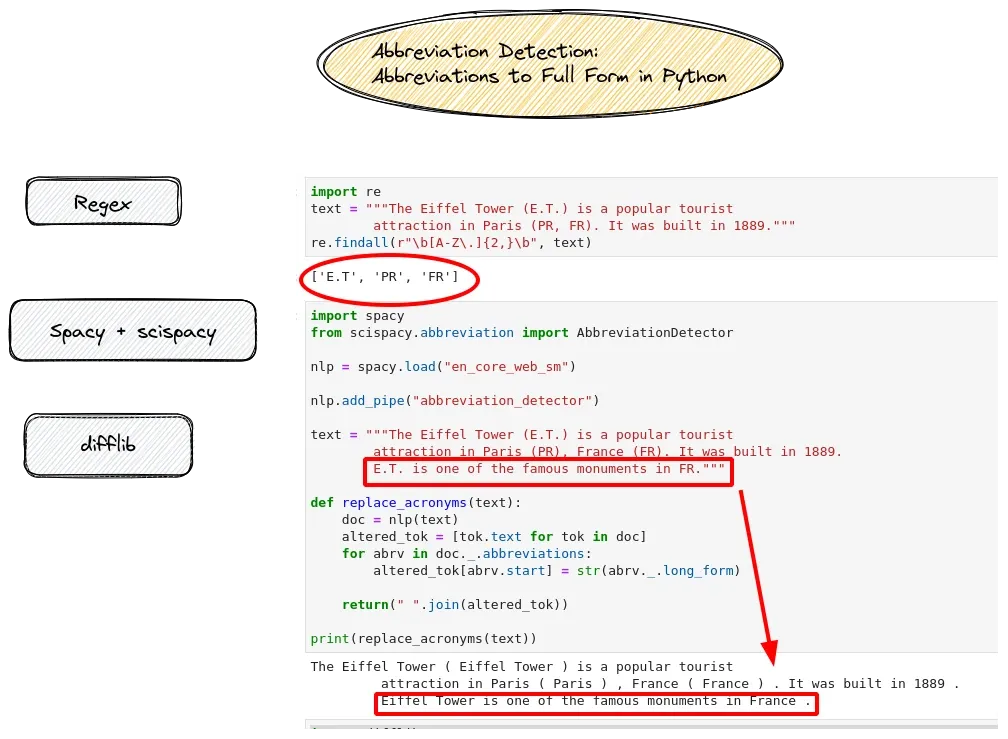
import re
text = """The Eiffel Tower (E.T.) is a popular tourist
attraction in Paris (PR, FR). It was built in 1889."""
re.findall(r"\b[A-Z\.]{2,}\b", text)
the result of this code is:
['E.T', 'PR', 'FR']
Regex to map abbreviation
We can build simple regex to map abbreviation to full names in Python: "(|.*\s)".join(abbrev.lower()). The code convert abbreviations to regex like:
- 'GET' -
g(|.*\s)e(|.*\s)t - 'ELC' -
e(|.*\s)l(|.*\s)c
Full code:
import re
def is_abbrev(abbrev, text):
pattern = "(|.*\s)".join(abbrev.lower())
return re.match("^" + pattern, text.lower()) is not None
teams = ['Elche', 'Girona', 'Getafe']
abbreviations = ['GET','ELC','GIR']
for team in teams:
for abbr in abbreviations:
match = is_abbrev(abbr, team)
if match:
print(abbr, team)
For a real world example for mapping football acronym to teams you can check: Football Prediction in Python: Barcelona vs Real Madrid
nlp abbreviation - fuzzy matching
We can also use fuzzy matching in order to map abbreviations to full form names in Python. Below you can find simple example of the matching:
from fuzzywuzzy import fuzz, process
teams = ['Elche', 'Girona', 'Getafe']
abbreviations = ['GET','ELC','GIR']
queries = [''.join([i[0] for i in j.split()]) for j in teams]
for query, company in zip(queries, teams):
print(company, '-', process.extractOne(query, abbreviations, scorer=fuzz.partial_token_sort_ratio))
for query, company in zip(queries, teams):
print(company, '-', process.extractOne(query, abbreviations, scorer=fuzz.partial_token_sort_ratio))
Result:
RM [('RMA', 100), ('BAR', 50), ('RSO', 50)]
RS [('RSO', 100), ('BAR', 50), ('RMA', 50)]
B [('BAR', 100), ('RMA', 0), ('RSO', 0)]
The second loop produce good results:
Real Madrid - ('RMA', 100)
Real Sociedad - ('RSO', 100)
Barcelona - ('BAR', 100)
Note: In some cases the code will produce bad results. For example for input:
teams = ['Elche', 'Girona', 'Getafe']
abbreviations = ['GET','ELC','GIR']
we will get:
E [('GET', 100), ('ELC', 100), ('GIR', 0)]
G [('GET', 100), ('GIR', 100), ('ELC', 0)]
G [('GET', 100), ('GIR', 100), ('ELC', 0)]
scispacy - AbbreviationDetector example
In this example scispacy detects abbreviations and acronyms and replace them in the text with the full form of the entities:
import spacy
from scispacy.abbreviation import AbbreviationDetector
nlp = spacy.load("en_core_web_sm")
nlp.add_pipe("abbreviation_detector")
text = """The Eiffel Tower (E.T.) is a popular tourist
attraction in Paris (PR), France (FR). It was built in 1889.
E.T. is one of the famous monuments in FR."""
def replace_acronyms(text):
doc = nlp(text)
altered_tok = [tok.text for tok in doc]
for abrv in doc._.abbreviations:
altered_tok[abrv.start] = str(abrv._.long_form)
return(" ".join(altered_tok))
replace_acronyms(text)
As a result we get replacement for all abbreviations/acronyms with the full forms:
- E.T. -> Eiffel Tower
- FR -> France
notice that in the result acronyms are replaced:
'The Eiffel Tower ( Eiffel Tower ) is a popular tourist
attraction in Paris ( Paris ) , France ( France ) . It was built in 1889 .
Eiffel Tower is one of the famous monuments in France .'
Difflib
Python offers one more way to match acronyms/abbreviations to names by similarity matching. We will use method get_close_matches('RSO', teams, n=3, cutoff=0.2) to find the closest match between two strings:
import difflib
teams = ['Real Madrid', 'Real Sociedad', 'Rayo Vallecano']
difflib.get_close_matches('RSO', teams, n=3, cutoff=0.2)
result:
['Real Sociedad']
Summary
We've seen three different ways of detecting and mapping abbreviations in Python. Let's have a quick overview of each of them, pointing out the advantages and disadvantages.
Regular expressions offer simplicity and freedom of customization. More general solutions like spacy, difflib and scispacy offer pre built models which can save precious time. They came at the cost of performance and efficiency.
For small to medium datasets we can use scispacy and the rest. For big data we need to implement custom solutions.