









To iterate pairwise or processing elements in groups of two in Python we can:
We can use the following syntax to margin on a single axis column or row in Pandas:
(1) Indexing - s -> (s0, s1), (s2, s3)
for i in range(0, len(lst) - 1, 2):
print(lst[i], lst[i + 1])
(2) zip and Slicing
for a, b in zip(lst[::2], lst[1::2]):
print(a, b)
(3) iter() and zip() - fastest
it = iter(lst)
for a, b in zip(it, it):
print(a, b)
(4) s -> (s0, s1), (s1, s2)
from itertools import pairwise
for a, b in pairwise(lst):
print(a, b)
Python provides multiple ways to achieve this, ranging from basic indexing to more advanced approaches using iterators and external libraries.
This article explores different techniques and benchmarks their performance.
1. Using Indexing (Basic Approach)
A simple way is to use a for loop with a step size of 2:
lst = [1, 2, 3, 4, 5, 6]
for i in range(0, len(lst) - 1, 2):
print(lst[i], lst[i + 1])
result:
1 2
3 4
5 6
Pros
- Simple and easy to understand.
- Flexible - works on any iterable of length ≥ 2.
Cons
- Requires explicit index handling.
- May raise an
IndexErrorif the list has an odd number of elements. - In case of list mutation might and in unexpected behavior
2. Using zip and Slicing
Another approach is to use zip() with slicing to pair elements:
for a, b in zip(lst[::2], lst[1::2]):
print(a, b)
result:
1 2
3 4
5 6
Pros
- More Pythonic and avoids explicit indexing.
- No risk of out-of-bounds indexing.
Cons
- Creates two temporary lists due to slicing, increasing memory usage.
3. Using iter() and zip() - fastest
By using iter() and zip(), we can efficiently pair elements without extra memory overhead:
it = iter(lst)
for a, b in zip(it, it):
print(a, b)
result:
1 2
3 4
5 6
Pros
- No need for slicing or extra lists.
- Uses iterators efficiently, saving memory.
- Works on any iterable (e.g., generators, files).
Cons
- Slightly less intuitive for beginners.
4. Using itertools.pairwise()
Python 3.10 introduced itertools.pairwise(), which simplifies this process:
from itertools import pairwise
for a, b in pairwise(lst):
print(a, b)
Note this time the result is different:
1 2
2 3
3 4
4 5
5 6
It will iterate over all pairs in this way:
s -> (s0, s1), (s1, s2), (s2, s3), ...
More info: itertools.pairwise(iterable)
Pros
- Cleanest and most Pythonic.
- Works with any iterable.
Cons
- Only available in Python 3.10+.
5. Using more_itertools.chunked()
If you're using the more-itertools library, chunked() offers a powerful way to split lists into fixed-size chunks:
from more_itertools import chunked
for a, b in chunked(lst, 2):
print(a, b)
Pros
- Works well for chunking lists into groups of any size.
Cons
- Requires an external library (
pip install more-itertools). - If the list has an odd number of elements, the last tuple will be incomplete.
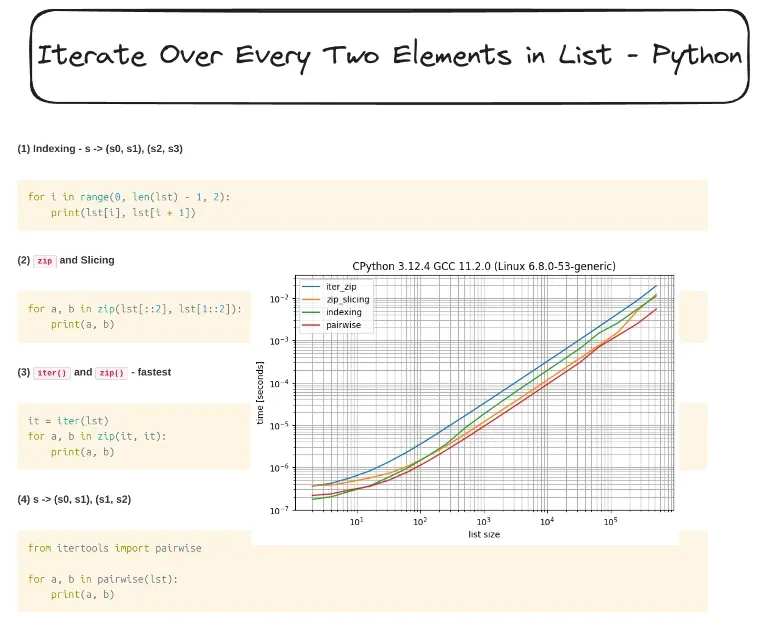
Performance Benchmark
Let's compare the performance of different methods using timeit:
import timeit
from itertools import pairwise
lst = list(range(100_000))
def method_indexing():
for i in range(0, len(lst) - 1, 2):
_ = lst[i], lst[i + 1]
def method_zip_slicing():
for a, b in zip(lst[::2], lst[1::2]):
_ = a, b
def method_iter_zip():
it = iter(lst)
for a, b in zip(it, it):
_ = a, b
def method_pairwise():
for a, b in pairwise(lst):
_ = a, b
print("Indexing:", timeit.timeit(method_indexing, number=100))
print("Zip + Slicing:", timeit.timeit(method_zip_slicing, number=100))
print("Iter + Zip:", timeit.timeit(method_iter_zip, number=100))
print("Pairwise (Python 3.10+):", timeit.timeit(method_pairwise, number=100))
Benchmark Results (Example on 1,000,000 items, Python 3.12)
| Method | Time (seconds) |
|---|---|
| Indexing | 3.78 |
| Zip + Slicing | 3.95 |
| Iter + Zip | 2.21 |
| Pairwise (3.10+) | 6.53 |
Key Takeaways:
zip(iter(), iter())is fastest for Python 3.9 and below.itertools.pairwise()is nearly as fast and more readable (Python 3.10+).zip()with slicing is slower due to extra memory allocation.
Conclusion
The best method depends on performance needs and readability:
- Use
zip(iter(), iter())for efficiency (Python 3.9 and below). - Use
itertools.pairwise()if on Python 3.10+. - Use basic indexing for simplicity in small scripts.