









In this guide, I'll show you several ways to merge/combine multiple CSV files into a single one by using Python (it'll work as well for text and other files). There will be bonus - how to merge multiple CSV files with one liner for Linux and Windows. Finally with a few lines of code you will be able to combine hundreds of files with full control of loaded data - you can convert all the CSV files into a Pandas DataFrame and then mark each row from which CSV file is coming.
Note: For JSON files check: How to Merge Multiple JSON Files Into Pandas DataFrame
Example files:
- data_201901.csv
- data_201902.csv
- data_201903.csv
expected output
merged.csv
Video Tutorial
Notebook with all examples: Softhints Github repo
Steps to merge multiple CSV(identical) files with Python
Note: that we assume - all files have the same number of columns and identical information inside
Short code example - concatenating all CSV files in Downloads folder:
import pandas as pd
import glob
path = r'~/Downloads'
all_files = glob.glob(path + "/*.csv")
all_files
Step 1: Import modules and set the working directory
First we will start with loading the required modules for the program and selecting working folder:
import os, glob
import pandas as pd
path = "/home/user/data/"
Step 2: Match CSV files by pattern
Next step is to collect all files needed to be combined. This will be done by:
all_files = glob.glob(os.path.join(path, "data_*.csv"))
The next code: data_*.csv match only files:
- starting with
data_ - with file extension
.csv
You can customize the selection for your needs having in mind that regex matching is used.
Step 3: Combine all files in the list and export as CSV
The final step is to load all selected files into a single DataFrame and converted it back to csv if needed:
df_merged = (pd.read_csv(f, sep=',') for f in all_files)
df_merged = pd.concat(df_from_each_file, ignore_index=True)
df_merged.to_csv( "merged.csv")
Note that you may change the separator by: sep=',' or change the headers and rows which to be loaded
You can find more about converting DataFrame to CSV file here: pandas.DataFrame.to_csv
Full Code
Below you can find the full code which can be used for merging multiple CSV files.
import os, glob
import pandas as pd
path = "/home/user/data/"
all_files = glob.glob(os.path.join(path, "data_*.csv"))
df_from_each_file = (pd.read_csv(f, sep=',') for f in all_files)
df_merged = pd.concat(df_from_each_file, ignore_index=True)
df_merged.to_csv( "merged.csv")
Steps to merge multiple CSV(identical) files with Python with trace
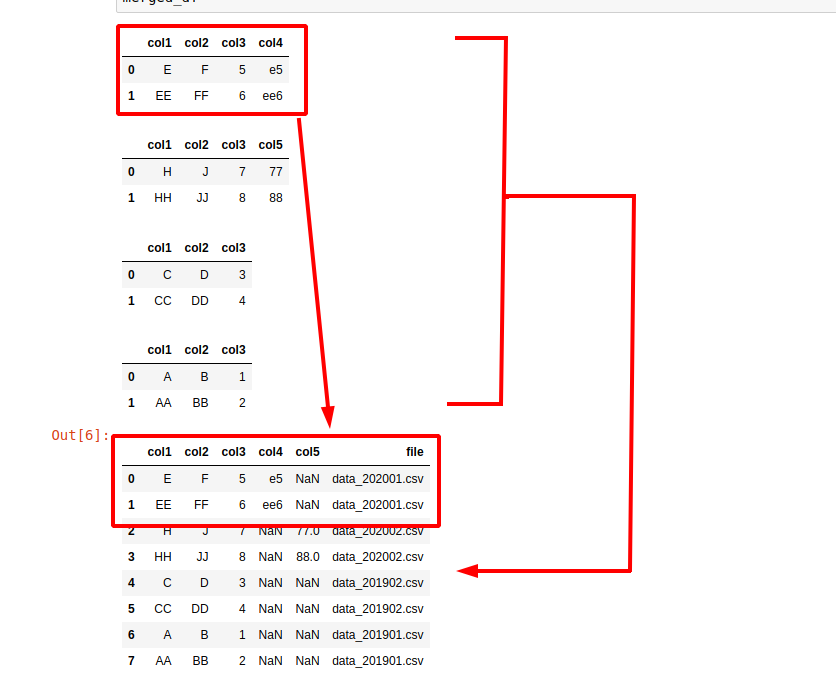
Now let's say that you want to merge multiple CSV files into a single DataFrame but also to have a column which represents from which file the row is coming. Something like:
| row | col | col2 | file |
|---|---|---|---|
| 1 | A | B | data_201901.csv |
| 2 | C | D | data_201902.csv |
This can be achieved very easy by small change of the code above:
import os, glob
import pandas as pd
path = "/home/user/data/"
all_files = glob.glob(os.path.join(path, "*.csv"))
all_df = []
for f in all_files:
df = pd.read_csv(f, sep=',')
df['file'] = f.split('/')[-1]
all_df.append(df)
merged_df = pd.concat(all_df, ignore_index=True, sort=True)
In this example we iterate over all selected files, then we extract the files names and create a column which contains this name.
Combine multiple CSV files when the columns are different
Sometimes the CSV files will differ for some columns or they might be the same only in the wrong order to be wrong. In this example you can find how to combine CSV files without identical structure:
import os, glob
import pandas as pd
path = "/home/user/data/"
all_files = glob.glob(os.path.join(path, "*.csv"))
all_df = []
for f in all_files:
df = pd.read_csv(f, sep=',')
df['file'] = f.split('/')[-1]
all_df.append(df)
merged_df = pd.concat(all_df, ignore_index=True, sort=True)
Pandas will align the data by this method: pd.concat. In case of a missing column the rows for a given CSV file will contain NaN values:
| row | col | col2 | col_201901 | file |
|---|---|---|---|---|
| 1 | A | B | AA | data_201901.csv |
| 2 | C | D | NaN | data_201902.csv |
If you need to compare two csv files for differences with Python and Pandas you can check: Python Pandas Compare Two CSV files based on a Column
More about pandas concat: pandas.concat
Bonus: Merge multiple files with Windows/Linux
Linux
For more details you can check: How to Merge multiple CSV Files in Linux Mint
Sometimes it's enough to use the tools coming natively from your OS or in case of huge files. Using python to concatenate multiple huge files might be challenging. In this case for Linux it can be used:
sed 1d data_*.csv > merged.csv
In this case we are working in the current folder by matching all files starting with data_. This is important because if you try to execute something like:
sed 1d *.csv > merged.csv
You will try to merge the newly output file as well which may cause issues. Another important note is that this will skip the first lines or headers of each file. In order to include headers you can do:
sed -n 1p data_1.csv > merged.csv
sed 1d data_*.csv >> merged.csv
If the commands above are not working for you then you can try with the next two. The first one will merge all csv files but have problems if the files ends without new line:
head -n 1 1.csv > combined.out && tail -n+2 -q *.csv >> merged.out
The second one will merge the files and will add new line at the end of them:
head -n 1 1.csv > combined.out
for f in *.csv; do tail -n 2 "$f"; printf "\n"; done >> merged.out
Windows
The Windows equivalent on this will be:
C:\> copy data_*.csv merged.csv
or
type data_*.csv > merged.csv