









To match either the end of a string ($) or a specific character with regex in Python you can use pattern like (?:char|$). This is useful when parsing structured text, extracting substrings, or validating input formats.
Regex Pattern: (?:char|$)
To match either a specific character or the end of the string, use the alternation (|) operator inside a non-capturing group ((?:...)):
(?:X|$)
Here, X is the specific character you want to match, and $ ensures that we also match the end of the string.
Explanation
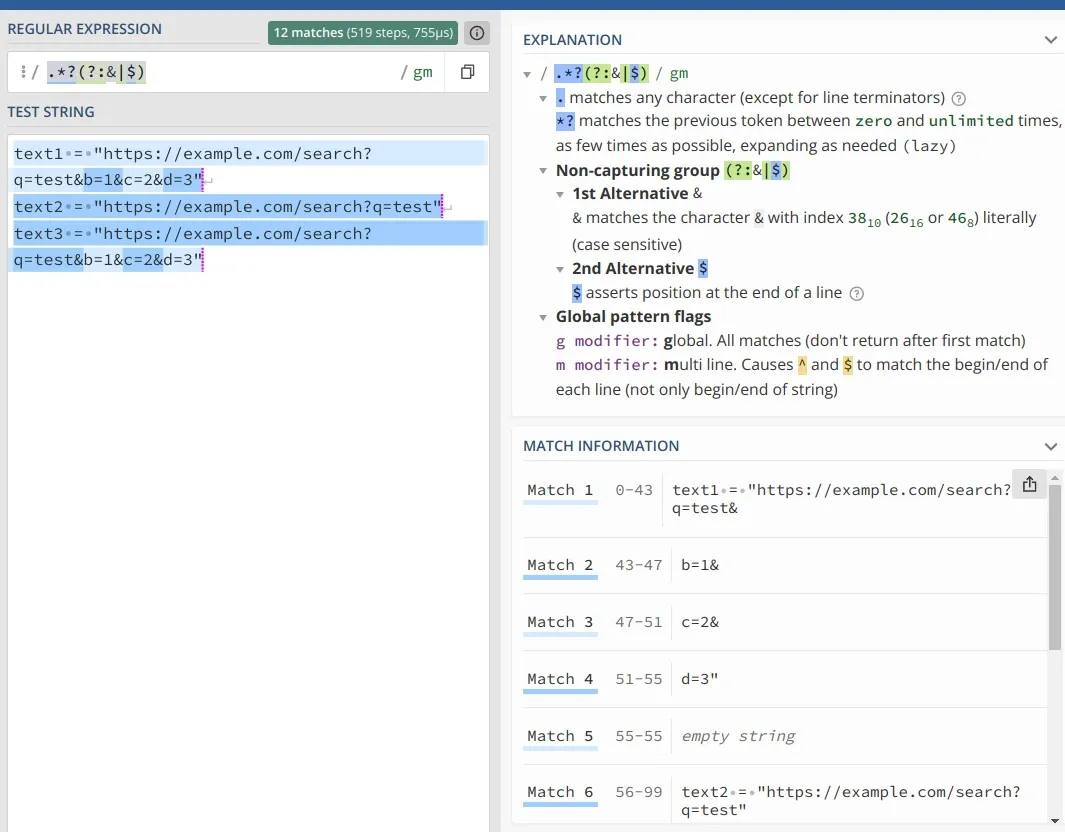
/.*?(?:&|$)/ gm
.matches any character (except for line terminators)*?matches the previous token between zero and unlimited times, as few times as possible, expanding as needed (lazy)- Non-capturing group
(?:&|$)- 1st Alternative &
& matches the character & with index 3810 (2616 or 468) literally (case sensitive) - 2nd Alternative $
$ asserts position at the end of a line
- 1st Alternative &
- Global pattern flags
- g modifier: global. All matches (don't return after first match)
- m modifier: multi line. Causes ^ and $ to match the begin/end of each line (not only begin/end of string)
1: Split a String at / or the End
If we want to split a string at backslash (/) or the end, this regex works:
import re
text1 = "https://example.com/search?q=test&b=1&c=2&d=3"
text2 = "https://example.com/search?q=test"
text3 = "https://example.com/search?q=test&b=1&c=2&d=3"
reg = r".*?(?:&|$)"
matches1 = re.findall(reg, text1)
matches2 = re.findall(reg, text2)
matches3 = re.match(reg, text3)
print(matches1)
print(matches2)
print(matches3)
result:
['https://example.com/search?q=test&', 'b=1&', 'c=2&', 'd=3', '']
['https://example.com/search?q=test', '']
<re.Match object; span=(0, 34), match='https://example.com/search?q=test&'>
In the example above we are extracting different parts from URL based on the matching condition - backslash or end of string.
You can test it in:
2: Extract Words Before . or End
If we want to extract words before a period (.) or the end, we use:
text1 = "hello.world.example"
text2 = "hello world"
matches1 = re.findall(r"[^.]+(?:\.|$)", text1)
matches2 = re.findall(r"[^.]+(?:\.|$)", text2)
print(matches1)
print(matches2)
result:
['hello.', 'world.', 'example']
['hello world']
3: Match Until : or End
To match a substring until a colon (:) or the end of the string:
text1 = "username:password"
text2 = "username-password"
match1 = re.search(r"^.*?(?=:|$)", text1)
match2 = re.search(r"^.*?(?=:|$)", text2)
print(match1.group())
print(match2.group())
output:
username
username-password
4. Extract everything between HTML tags
For example we can extract everything between two tags: <a> and </a>. The regex below will match the start and the end of the links:
<a\b[^>]*>(.*?)</a>
Conclusion
Using (?:char|$), we can efficiently match either a specific character or the end of a string, making regex patterns more flexible for text processing.