









Need to match strings which don't start with a given pattern using a regular expression in Python?
If so, you may use the following syntax to find all strings except ones which don't start with https:
r"^(?!https).*"
Step 1: Match strings not starting with pattern
IN this example we have a list of URLs. Let's say that you would like to get all of them which don't start with https.
For this purpose we will use negative lookahead:
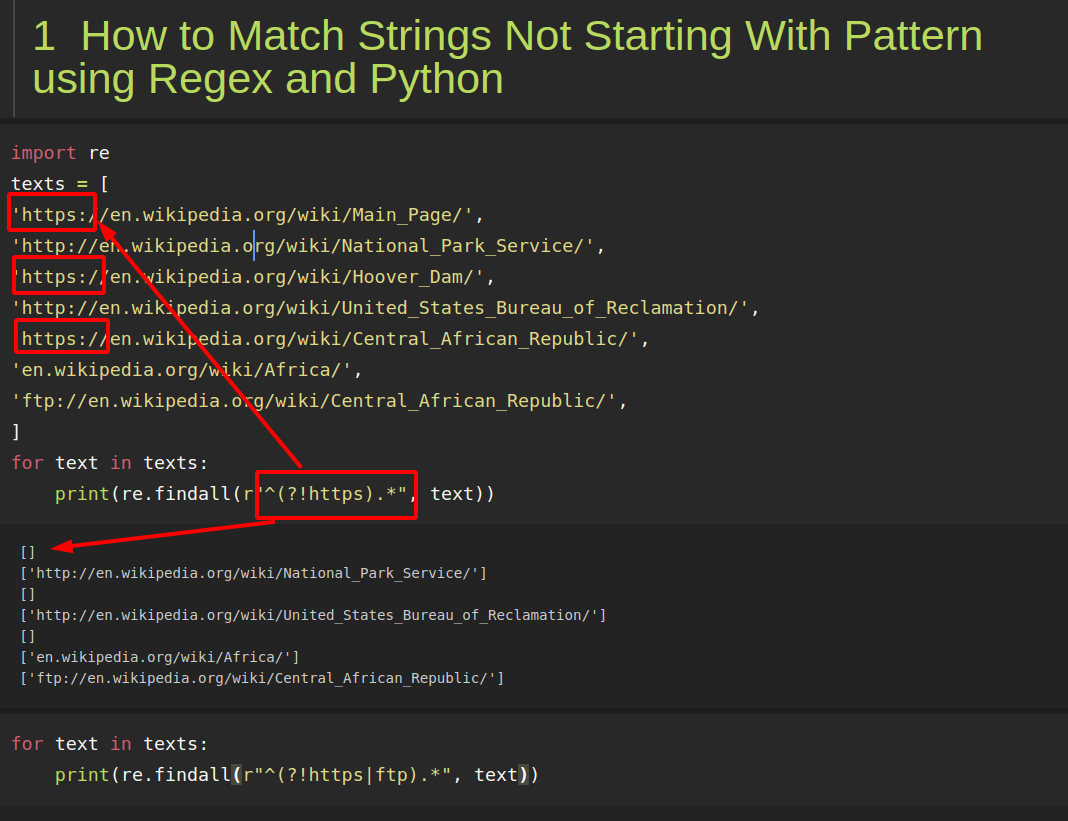
import re
texts = [
'https://en.wikipedia.org/wiki/Main_Page/',
'http://en.wikipedia.org/wiki/National_Park_Service/',
'https://en.wikipedia.org/wiki/Hoover_Dam/',
'http://en.wikipedia.org/wiki/United_States_Bureau_of_Reclamation/',
'https://en.wikipedia.org/wiki/Central_African_Republic/',
'en.wikipedia.org/wiki/Africa/',
'ftp://en.wikipedia.org/wiki/Central_African_Republic/',
]
for text in texts:
print(re.findall(r"^(?!https).*", text))
The result is:
[]
['http://en.wikipedia.org/wiki/National_Park_Service/']
[]
['http://en.wikipedia.org/wiki/United_States_Bureau_of_Reclamation/']
[]
['en.wikipedia.org/wiki/Africa/']
['ftp://en.wikipedia.org/wiki/Central_African_Republic/']
How does it work?
^- asserts position at start of the string(?!https)- Negative Lookahead - assert that the regex does not match - https.*- matches any character between zero and unlimited times
Step 2: Match strings not starting with several patterns
Now let try to find all strings which don't start with:
- https
- ftp
We can use | which is or in regex syntax - r"^(?!https|ftp).*":
for text in texts:
print(re.findall(r"^(?!https|ftp).*", text))
result is:
[]
['http://en.wikipedia.org/wiki/National_Park_Service/']
[]
['http://en.wikipedia.org/wiki/United_States_Bureau_of_Reclamation/']
[]
['en.wikipedia.org/wiki/Africa/']
[]
Note: you can add many patterns with |.
Step 3: Match strings not starting with list of characters
Finally let's see how to match all strings that don't start with several characters like:
fh
This time we are going to list all characters between square brackets: [^hf]. Statement [hf] means match letters - f or h while ^ negates the match.
In other words match a single character not present in the list - [hf].
So we can use:
for text in texts:
print(re.findall(r"^[^hf].*", text))
Which will give us:
[]
[]
[]
[]
[]
['en.wikipedia.org/wiki/Africa/']
[]