









This post describes how to DataFrame sampling in Pandas works: basics, conditionals and by group. You can use the following code in order to get random sample of DataFrame by using Pandas and Python:
df.sample()
The rest of the article contains explanation of the functions, advanced examples and interesting use cases. Check it if you want to dive deeper into data sampling with Pandas.
Steps to generate random sample of data with Pandas
Step 1: Random sampling of rows(columns) from DataFrame by sample()
The easiest way to generate random set of rows with Python and Pandas is by: df.sample. By default returns one random row from DataFrame:
# Default behavior of sample()
df.sample()
result:
row3433
If you like to get more than a single row than you can provide a number as parameter:
# return n rows
df.sample(3)
result:
row23
row2256
row4774
It can be applied for rows by using axis=1 as shown below.
# columns
df.sample(3, axis=1).head()
result:
col11, col2, col7
If you like to get a fraction (or percentage of your data) than you can use parameter fraction. In the example below dataset has 5000 rows and 0.001 will return exactly 5 random rows:
# The fraction of rows and columns: frac
df.sample(frac=0.001)
Finally you can provide seed for the better randomization - random_state
# sample with seed
df.sample(n=3, random_state=5)
This is the explanation of this parameter:
random_state : int or numpy.random.RandomState, optional
Seed for the random number generator (if int), or numpy RandomState object.
Step 2: Get random rows with np.random.choice
As alternative or if you want to engineer your own random mechanism you can use np.random.choice - in order to generate sample of index numbers and later to check/amend the selection. Finally you can access by iloc:
import numpy as np
random_idx = np.random.choice(1000, replace=False, size=5)
df.iloc[random_idx]
result:
646 Color ..
550 Color ..
Note: That using: np.random.choice(1000, limit the selection to first 1000 rows!
Step 3: Random sample of rows based on column value
The final step of data sampling with Pandas is the case when you have condition based on the values of a given column. Let say that you have column with several values:
- color
- black/white
and you want to get 3 samples for the first type and 3 for the second. The code below will show you how to achieve this:
col = 'color'
for typ in list(df[col].dropna().unique()):
print(typ, end=' - ')
display(df[df[col] == typ].sample(3))
output is like:
Color -
2867 Color ..
4345 Color ..
764 Color ..
Black and White -
286 Black and White ..
3904 Black and White ..
1595 Black and White ..
...
In case of more values in the column and if you like to get only one random row per kind from this DataFrame - you can use the code below:
col = 'content_rating'
sample = []
variants = list(df[col].dropna().unique())
print(variants)
for typ in variants:
sample.append(df[df[col] == typ].sample())
pd.concat(sample)
which result in:
['PG-13', 'PG', 'G', 'R', 'TV-14', 'TV-PG', 'TV-MA', 'TV-G', 'Not Rated', 'Unrated', 'Approved', 'TV-Y', 'NC-17', 'X', 'TV-Y7', 'GP', 'Passed', 'M']
1514 ..
4526 ..
2686 ..
..
One sample row per each variation in column - content_rating - group and displayed as a single DataFrame.
Step 4: Conditional DataFrame sampling with numpy and weights
Lets work again with the same column color and this time to sample rows all except - 'Color' - in this case we can use np.where in order to built weights. This weights will be passed to method sample which is going to generate samples based on our weighted list:
# excluding 'Color' values by applying weights 0 - Color and 1 - rest
df['weights'] = np.where(df['color'] == 'Color', .0, 1)
df.sample(frac=.001, weights='weights')
result in:
4846 NaN ..
4370 Black and White ..
...
In case that we need to get random rows only for 'Color' then we can do:
# Including only 'Color' values by applying weights 1 - Color and 0 - rest
df['weights'] = np.where(df['color'] == 'Color', 1, 0.0)
df.sample(frac=.001, weights='weights')
result in:
3036 Color ..
4632 Color ..
...
How the conditional sampling with np.where works? You can understand from the code below:
np.where(df['color'] == 'Color', 1, 0)[270:280]
print(list(df['color'][270:280]))
This produce the following weights which are passed to the sample method:
array([1, 1, 0, 1, 1, 1, 1, 1, 1, 0])
['Color', 'Color', ' Black and White', 'Color', 'Color', 'Color', 'Color', 'Color', 'Color', nan]
So in case of matched condition the first value is applied - 1, otherwise the second one. This list is passed as probability to the sampling method which generate the data based on it.
This is the official explanation:
weights : str or ndarray-like, optional
Default ‘None’ results in equal probability weighting. If passed a Series, will align with target object on index. Index values in weights not found in sampled object will be ignored and index values in sampled object not in weights will be assigned weights of zero. If called on a DataFrame, will accept the name of a column when axis = 0. Unless weights are a Series, weights must be same length as axis being sampled. If weights do not sum to 1, they will be normalized to sum to 1. Missing values in the weights column will be treated as zero. Infinite values not allowed.
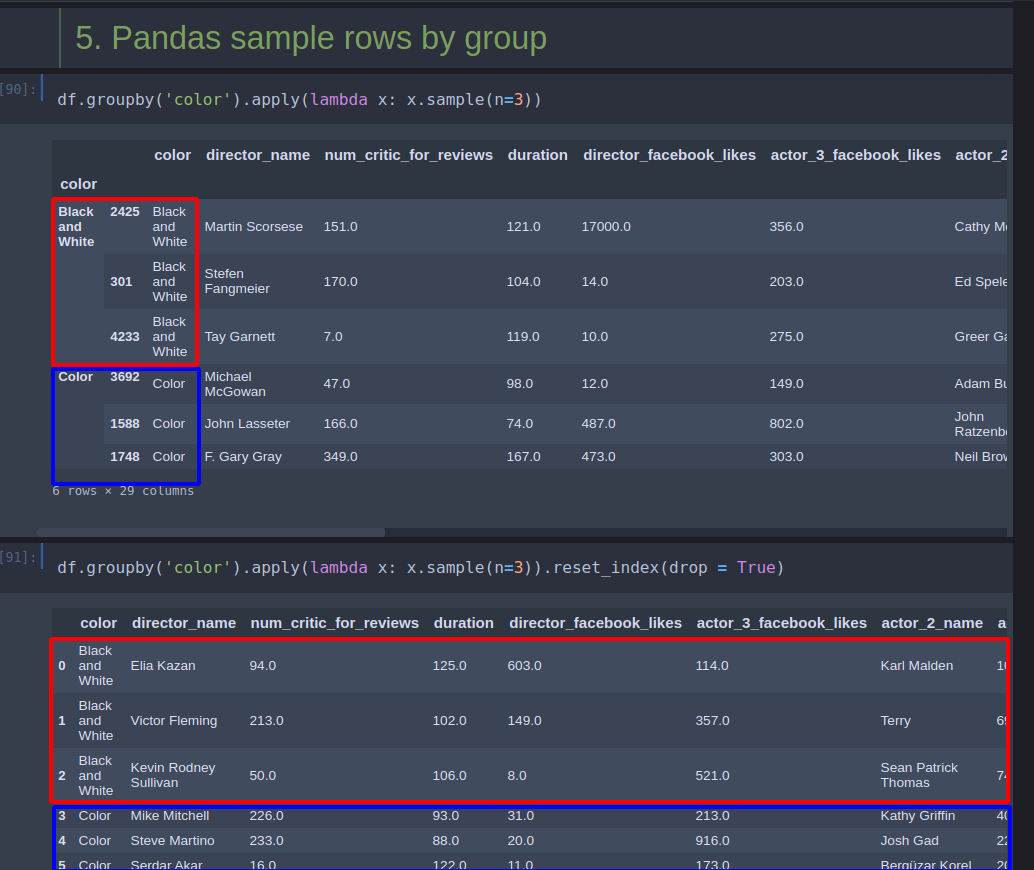
Step 5: Pandas sample rows by group
At this step we are going to group the rows by column and then apply a lambda in order to call sample with 3 rows per group:
df.groupby('color').apply(lambda x: x.sample(n=3))
If you need to reset the index you can do it by: reset_index(drop=True)
df.groupby('color').apply(lambda x: x.sample(n=3)).reset_index(drop = True)
The result is visible on this picture:
Bonus: Pandas DataFrame combine head() and tail()
Sometimes sampling start with the getting the first and the last rows of a DataFrame. For this purpose df.head(2) and df.tail(2) can be used. If you want to combine them in a single line you can use append and get the result as:
# combine head and tail variant 1
rows = 2
df.head(rows).append(df.tail(rows))
result:
0 Color ..
1 Color ..
5041 Color ..
5042 Color ..