









Need to parse XML sitemap of a website in Python and Pandas? To get all URLs as a Pandas DataFrame?
If so, you may find several very useful solutions in this article.
Option 1: Parse XML Sitemap with Python and Pandas
The sitemap which we are going to read is the one of this website:
/sitemap.xml
We are going to read it in Python with library requests and then parse the URLs and the dates by module lxml.
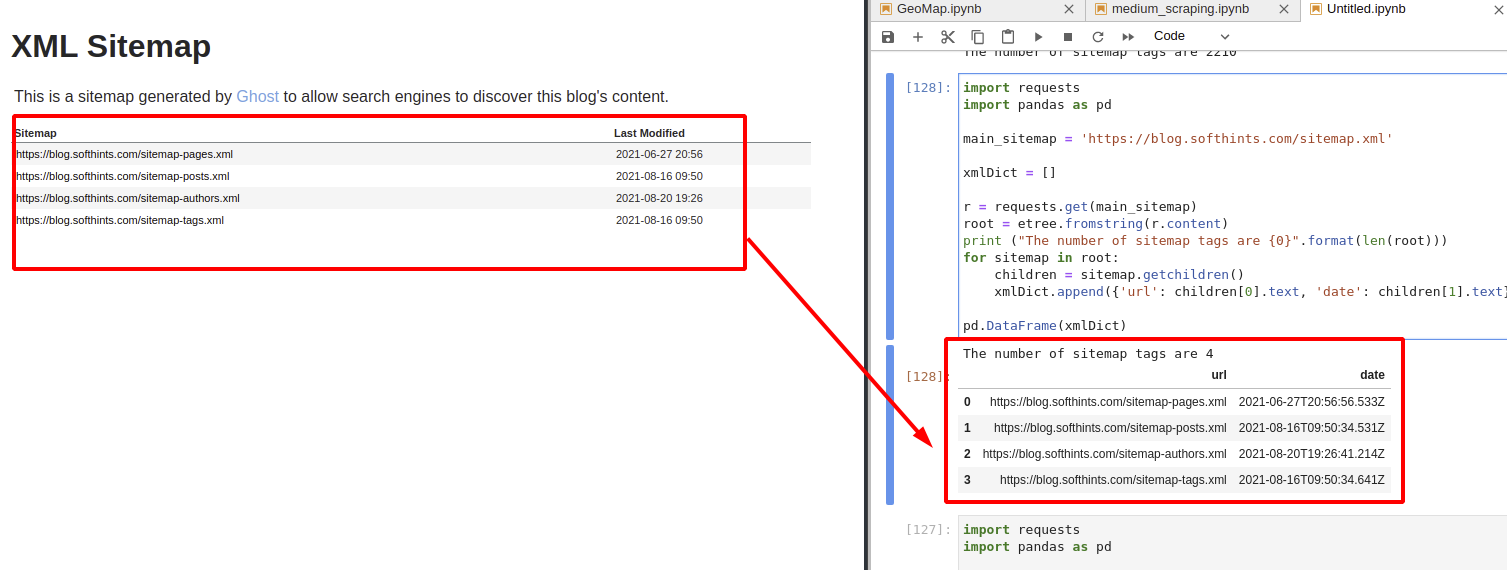
You can find the code below - first we read the sitemap with package requests. Next we load the content into lxml creating a tree for all elements.
Finally we are iterating over all elements in the sitemap and append the info to a dict:
import requests
import pandas as pd
from lxml import etree
main_sitemap = 'https://blog.softhints.com/sitemap.xml'
xmlDict = []
r = requests.get(main_sitemap)
root = etree.fromstring(r.content)
print ("The number of sitemap tags are {0}".format(len(root)))
for sitemap in root:
children = sitemap.getchildren()
xmlDict.append({'url': children[0].text, 'date': children[1].text})
pd.DataFrame(xmlDict)
The result is a Pandas DataFrame which contains the URLs and the dates of the sitemap:
Option 2: Parse compressed XML Sitemap with Python
In this option we will take care of a sitemap which is compressed. The parsing is pretty similar but includes one additional step - extraction:
import requests
import gzip
from io import StringIO
r = requests.get('http://blog.softhints.com/sitemap.xml.gz')
sitemap = gzip.GzipFile(fileobj=StringIO(r.content)).read()
We are going to use StringIO from io in order to read the content of the compressed XML sitemap.
Then we can parse it in the same way like in Option 1.
Option 3: Parse local XML Sitemap with Python - no namespaces
Sometimes you need to parse with Python a sitemap which is stored locally on your machine.
Suppose you have a local file with content like and named - XML Sitemap.xml:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="//blog.softhints.com/sitemap.xsl"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>https://blog.softhints.com/sitemap-pages.xml</loc>
<lastmod>2021-06-27T20:56:56.533Z</lastmod>
</sitemap>
<sitemap>
<loc>https://blog.softhints.com/sitemap-posts.xml</loc>
<lastmod>2021-08-16T09:50:34.531Z</lastmod>
</sitemap>
<sitemap>
<loc>https://blog.softhints.com/sitemap-authors.xml</loc>
<lastmod>2021-08-20T19:26:41.214Z</lastmod>
</sitemap>
<sitemap>
<loc>https://blog.softhints.com/sitemap-tags.xml</loc>
<lastmod>2021-08-16T09:50:34.641Z</lastmod>
</sitemap>
</sitemapindex>
To parse the above sitemap without taking care for the namespaces you can use the next Python code:
import lxml.etree
tree = lxml.etree.parse("/home/myuser/Desktop/XML Sitemap.xml")
for url in tree.xpath("//*[local-name()='loc']/text()"):
print(url)
for date in tree.xpath("//*[local-name()='lastmod']/text()"):
print(date)
This will print the urls and the dates as:
https://blog.softhints.com/sitemap-pages.xml
https://blog.softhints.com/sitemap-posts.xml
https://blog.softhints.com/sitemap-authors.xml
https://blog.softhints.com/sitemap-tags.xml
2021-06-27T20:56:56.533Z
2021-08-16T09:50:34.531Z
2021-08-20T19:26:41.214Z
2021-08-16T09:50:34.641Z
Note: If you need to find all elements and print their values you can use method root.iter():
for i in root.iter():
print(i.text)
Option 4: Parse local XML Sitemap with Python - namespaces
If you need to parse XML sitemap with namespaces you can use method root.findall and give the namespace as a path.
In order to find what is your namespace you can test the root element by:
tree.getroot()
the result is:
<Element '{http://www.sitemaps.org/schemas/sitemap/0.9}sitemapindex' at 0x7fe25fbdd720>
So the namespace which we are going to use is {http://www.sitemaps.org/schemas/sitemap/0.9} and we are searching for this element sitemap.
The code below parse the XML sitemap which is stored locally but it will work also with requests:
import xml.etree.ElementTree as ET
tree = ET.parse("/home/myuser/Desktop/XML Sitemap.xml")
root = tree.getroot()
# In find/findall, prefix namespaced tags with the full namespace in braces
for sitemap in root.findall('{http://www.sitemaps.org/schemas/sitemap/0.9}sitemap'):
loc = sitemap.find('{http://www.sitemaps.org/schemas/sitemap/0.9}loc').text
lastmod = sitemap.find('{http://www.sitemaps.org/schemas/sitemap/0.9}lastmod').text
print(loc, lastmod)
The parsed sitemap content is shown below:
https://blog.softhints.com/sitemap-pages.xml 2021-06-27T20:56:56.533Z
https://blog.softhints.com/sitemap-posts.xml 2021-08-16T09:50:34.531Z
https://blog.softhints.com/sitemap-authors.xml 2021-08-20T19:26:41.214Z
https://blog.softhints.com/sitemap-tags.xml 2021-08-16T09:50:34.641Z