









In this post:
- Python extract text from image
- Python OCR(Optical Character Recognition) for PDF
- Python extract text from multiple images in folder
- How to improve the OCR results
Python's binding pytesseract for tesserct-ocr is extracting text from image or PDF with great success:
str = pytesseract.image_to_string(file, lang='eng')
You can watch video demonstration of extraction from image and then from PDF files:
- Python extract text from image or pdf
- Extract tabular data from PDF with Python - Tabula, Camelot, PyPDF2
- Examples of extraction for tabular data with python
You could find interesting this summary python post: Python useful tips and reference project
Extract text from image
Below you can find simple python 3 example of reading image file and outputting the text to the console. You will need to import pil and pytesseract:
from PIL import Image
import pytesseract
file = Image.open("/home/user/sample.png")
str = pytesseract.image_to_string(file, lang='eng')
print(str)
You need to add language parameter like:
- fra - French
- eng - English
- spa - Spanish
- rus - Russian
- deu - German
Here you can find list of other languages:
Required Libraries
In order the code above to work you may need(unless you have them) the following additional packages. You need to run this in your terminal or pip console:
- install tesseract-ocr:
sudo apt-get install tesseract-ocr
- install pill and pytesseract(used for connection to tesseract-ocr):
pip install pillow
pip install pytesseract
Python OCR(Optical Character Recognition) for PDF
OCR or text extraction from PDF is divided in several steps:
- open the PDF file with wand / imagemagick
- convert the PDF to images
- read images one by one and extract the text with pytesseract / tesserct-ocr
import io
from PIL import Image
import pytesseract
from wand.image import Image as wi
pdfFile = wi(filename = ""/home/user/sample.pdf"", resolution = 300)
image = pdfFile.convert('jpeg')
imageBlobs = []
for img in image.sequence:
imgPage = wi(image = img)
imageBlobs.append(imgPage.make_blob('jpeg'))
extract = []
for imgBlob in imageBlobs:
image = Image.open(io.BytesIO(imgBlob))
text = pytesseract.image_to_string(image, lang = 'eng')
extract.append(text)
print(extract)
Required Libraries
Only for PDF example you need to install imagemagick binding of python 3:
pip install wand
Python OCR multiple images in folder:
If you have more than one image you can iterate over all and extract the text by os.walk. Then open image by image and extract the text:
from PIL import Image
import pytesseract
import os
indir = r'/home/user/photos/'
for root, dirs, filenames in os.walk(indir):
for filename in filenames:
print('#####################################' + filename + '#####################################')
im = Image.open(indir + filename)
text = pytesseract.image_to_string(im, lang='eng')
print(text)
How to improve the OCR results
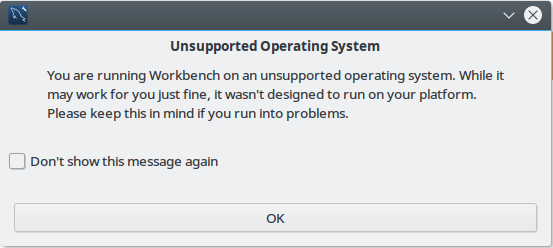
Use white color themes (dark text on white background)
Below you can see two examples of a good and a bad image containing one and the same text but giving completely different results:
The good version is and the ouput is:
Unsupported Operating System
You are running Workbench on an unsupported operating system. While it
may work for you just fine, it wasn't designed to run on your platform.
Please keep this in mind if you run into problems.
(© Don't show this message again
OK
While the bad example is here and the result is:
De ee ec Ec
Ses en anche eu
it may work for you just fine, it wasn't designed to run on your platform.
ee oe Sn ere ces
De ee
ir
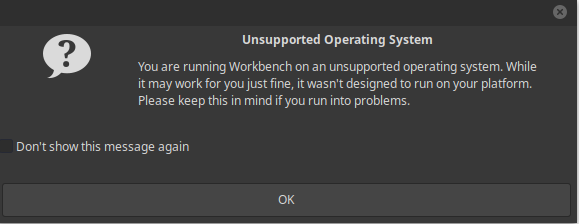
The lighter version is performing much better in comparison to the dark one.
Scale the image to the optimal size
Depending on the image you can increase the size of the image: double the width and height. This could improve the OCR recognition by PyTesseract significantly for some images. There is a really nice and comprehensive article here:
Improve OCR Accuracy With Advanced Image Preprocessing
In short the practical tips are:
- remove noise and useless information
- increase contract
- choose the right size
- get the best possible image quality